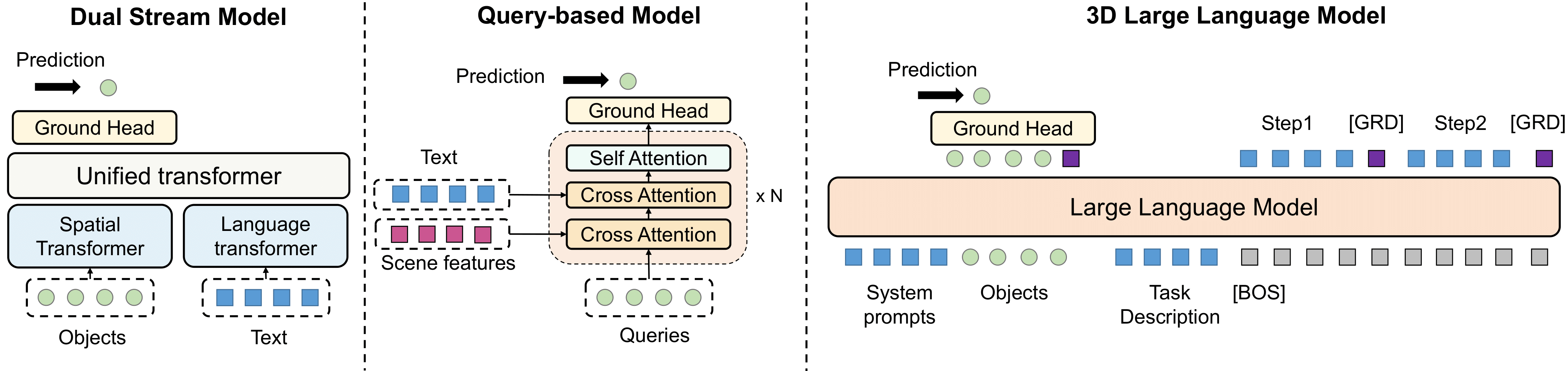
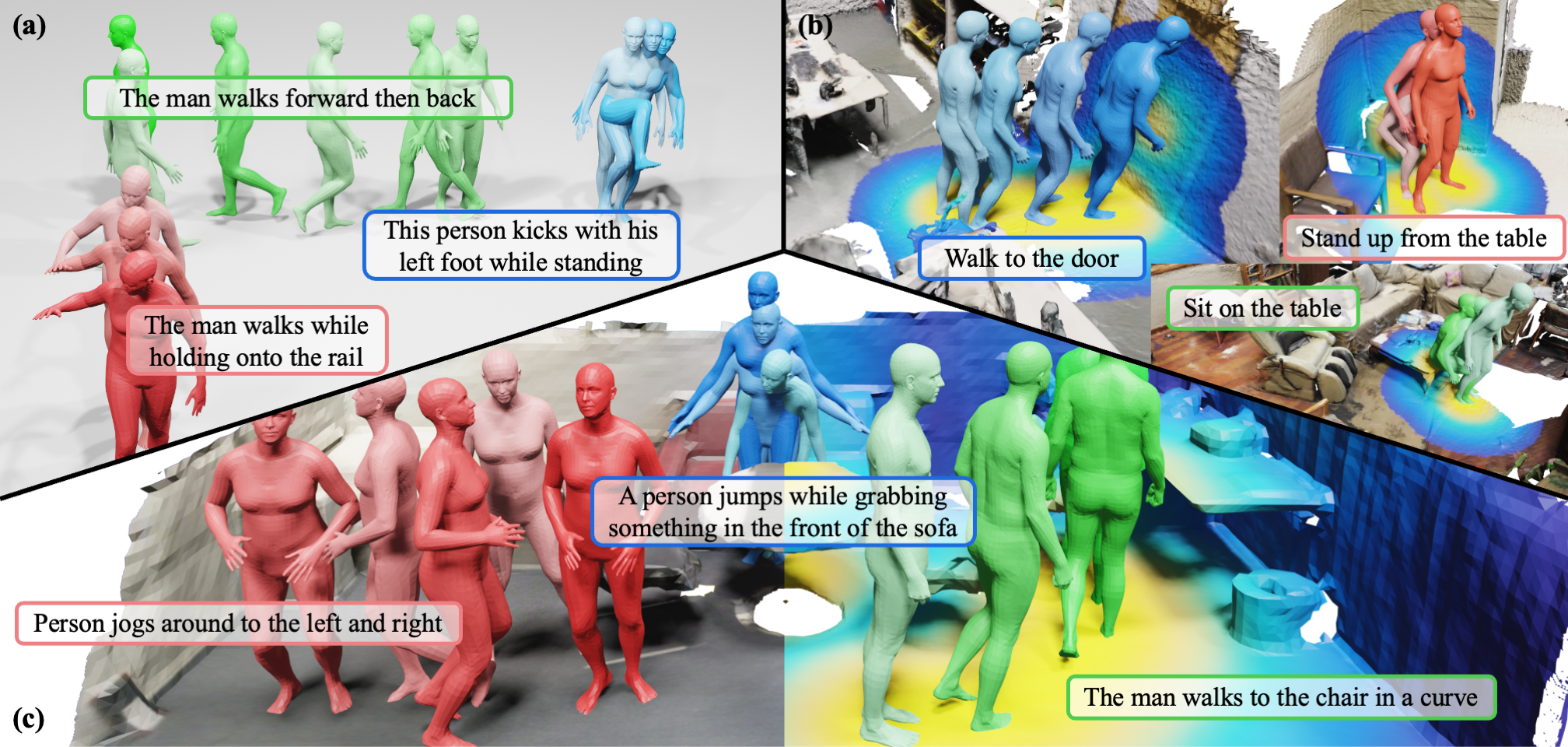
Grounding natural language in physical 3D environments is essential for the advancement of embodied artificial intelligence. Current datasets and models for 3D visual grounding predominantly focus on identifying and localizing objects from static, object-centric descriptions. These approaches do not adequately address the dynamic and sequential nature of task-oriented grounding necessary for practical applications. In this work, we propose a new task: Task-oriented Sequential Grounding in 3D scenes, wherein an agent must follow detailed step-by-step instructions to complete daily activities by locating a sequence of target objects in indoor scenes. To facilitate this task, we introduce SG3D, a large-scale dataset containing 22,346 tasks with 112,236 steps across 4,895 real-world 3D scenes. The dataset is constructed using a combination of RGB-D scans from various 3D scene datasets and an automated task generation pipeline, followed by human verification for quality assurance. We adapted three state-of-the-art 3D visual grounding models to the sequential grounding task and evaluated their performance on SG3D. Our results reveal that while these models perform well on traditional benchmarks, they face significant challenges with task-oriented sequential grounding, underscoring the need for further research in this area.
@article{zhang2024task,title={Task-oriented Sequential Grounding in 3D Scenes},author={Zhang, Zhuofan and Zhu, Ziyu and Li, Pengxiang and Liu, Tengyu and Ma, Xiaojian and Chen, Yixin and Jia, Baoxiong and Huang, Siyuan and Li, Qing},journal={arXiv},year={preprint}}
The human hand’s complex kinematics allow for simultaneous grasping and manipulation of multiple objects, essential for tasks like object transfer and in-hand manipulation. Despite its importance, robotic multi-object grasping remains underexplored and presents challenges in kinematics, dynamics, and object configurations. This paper introduces MultiGrasp, a two-stage method for multi-object grasping on a tabletop with a multi-finger dexterous hand. It involves (i) generating pre-grasp proposals and (ii) executing the grasp and lifting the objects. Experimental results primarily focus on dual-object grasping and report a 44.13% success rate, showcasing adaptability to unseen object configurations and imprecise grasps. The framework also demonstrates the capability to grasp more than two objects, albeit at a reduced inference speed.
@article{li2023grasp,title={Grasp Multiple Objects with One Hand},author={Li, Yuyang and Liu, Bo and Geng, Yiran and Li, Puhao and Yang, Yaodong and Zhu, Yixin and Liu, Tengyu and Huang, Siyuan},journal={RA-L},honor={Oral Presentation},year={2024}}
IROS
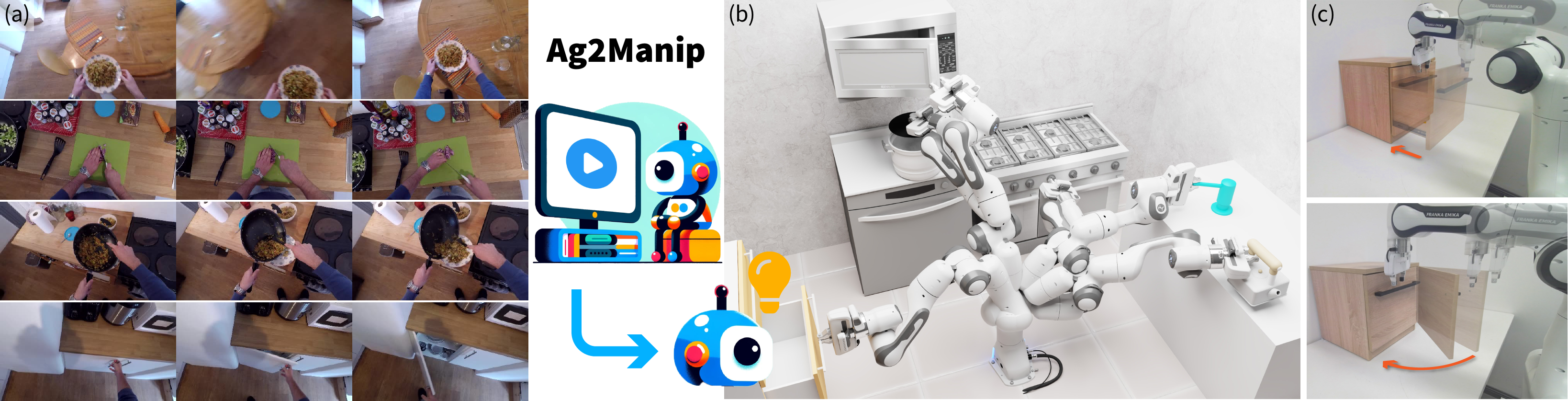
Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations
Enhancing the ability of robotic systems to autonomously acquire novel manipulation skills is vital for applications ranging from assembly lines to service robots. Existing methods (e.g., VIP, R3M) rely on learning a generalized representation for manipulation tasks but overlook (i) the domain gap between distinct embodiments and (ii) the sparseness of successful task trajectories within the embodiment-specific action space, leading to misaligned and ambiguous task representations with inferior learning efficiency. Our work addresses the above challenges by introducing Ag2Manip (Agent-Agnostic representations for Manipulation) for learning novel manipulation skills. Our approach encompasses two principal innovations: (i) a novel agent-agnostic visual representation trained on human manipulation videos with embodiments masked to ensure generalizability, and (ii) an agent-agnostic action representation that abstracts the robot’s kinematic chain into an agent proxy with a universally applicable action space to focus on the core interaction between the end-effector and the object. Through our experiments, Ag2Manip demonstrates remarkable improvements across a diverse array of manipulation tasks without necessitating domain-specific demonstrations, substantiating a significant 325% improvement in average success rate across 24 tasks from FrankaKitchen, ManiSkill, and PartManip. Further ablation studies underscore the critical role of both representations in achieving such improvements.
@article{li2024ag2manip,title={Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations},author={Li, Puhao and Liu, Tengyu and Li, Yuyang and Han, Muzhi and Geng, Haoran and Wang, Shu and Zhu, Yixin and Zhu, Song-Chun and Huang, Siyuan},booktitle={Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},journal={IROS},honor={Oral Pitch},year={2024}}
ECCV
Sceneverse: Scaling 3d vision-language learning for grounded scene understanding
3D vision-language grounding, which focuses on aligning language with the 3D physical environment, stands as a cornerstone in the development of embodied agents. In comparison to recent advancements in the 2D domain, grounding language in 3D scenes faces several significant challenges: (i) the inherent complexity of 3D scenes due to the diverse object configurations, their rich attributes, and intricate relationships; (ii) the scarcity of paired 3D vision-language data to support grounded learning; and (iii) the absence of a unified learning framework to distill knowledge from grounded 3D data. In this work, we aim to address these three major challenges in 3D vision-language by examining the potential of systematically upscaling 3D vision-language learning in indoor environments. We introduce the first million-scale 3D vision-language dataset, SceneVerse, encompassing about 68K 3D indoor scenes and comprising 2.5M vision-language pairs derived from both human annotations and our scalable scene-graph-based generation approach. We demonstrate that this scaling allows for a unified pre-training framework, Grounded Pre-training for Scenes (GPS), for 3D vision-language learning. Through extensive experiments, we showcase the effectiveness of GPS by achieving state-of-the-art performance on all existing 3D visual grounding benchmarks. The vast potential of SceneVerse and GPS is unveiled through zero-shot transfer experiments in the challenging 3D vision-language tasks.
@article{jia2024sceneverse,title={Sceneverse: Scaling 3d vision-language learning for grounded scene understanding},author={Jia, Baoxiong and Chen, Yixin and Yu, Huangyue and Wang, Yan and Niu, Xuesong and Liu, Tengyu and Li, Qing and Huang, Siyuan},booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},data={https://forms.gle/AXMk7MH6bFXpCqd99},journal={ECCV},year={2024}}
CVPR
AnySkill: Learning Open-Vocabulary Physical Skill for Interactive Agents
Traditional approaches in physics-based motion generation, centered around imitation learning and reward shaping, often struggle to adapt to new scenarios. To tackle this limitation, we propose AnySkill, a novel hierarchical method that learns physically plausible interactions following open-vocabulary instructions. Our approach begins by developing a set of atomic actions via a low-level controller trained via imitation learning. Upon receiving an open-vocabulary textual instruction, AnySkill employs a high-level policy that selects and integrates these atomic actions to maximize the CLIP similarity between the agent’s rendered images and the text. An important feature of our method is the use of image-based rewards for the high-level policy, which allows the agent to learn interactions with objects without manual reward engineering. We demonstrate AnySkill’s capability to generate realistic and natural motion sequences in response to unseen instructions of varying lengths, marking it the first method capable of open-vocabulary physical skill learning for interactive humanoid agents.
@article{cui2024anyskill,title={AnySkill: Learning Open-Vocabulary Physical Skill for Interactive Agents},author={Cui, Jieming and Liu, Tengyu and Liu, Nian and Yang, Yaodong and Zhu, Yixin and Huang, Siyuan},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},journal={CVPR},year={2024}}
CVPR
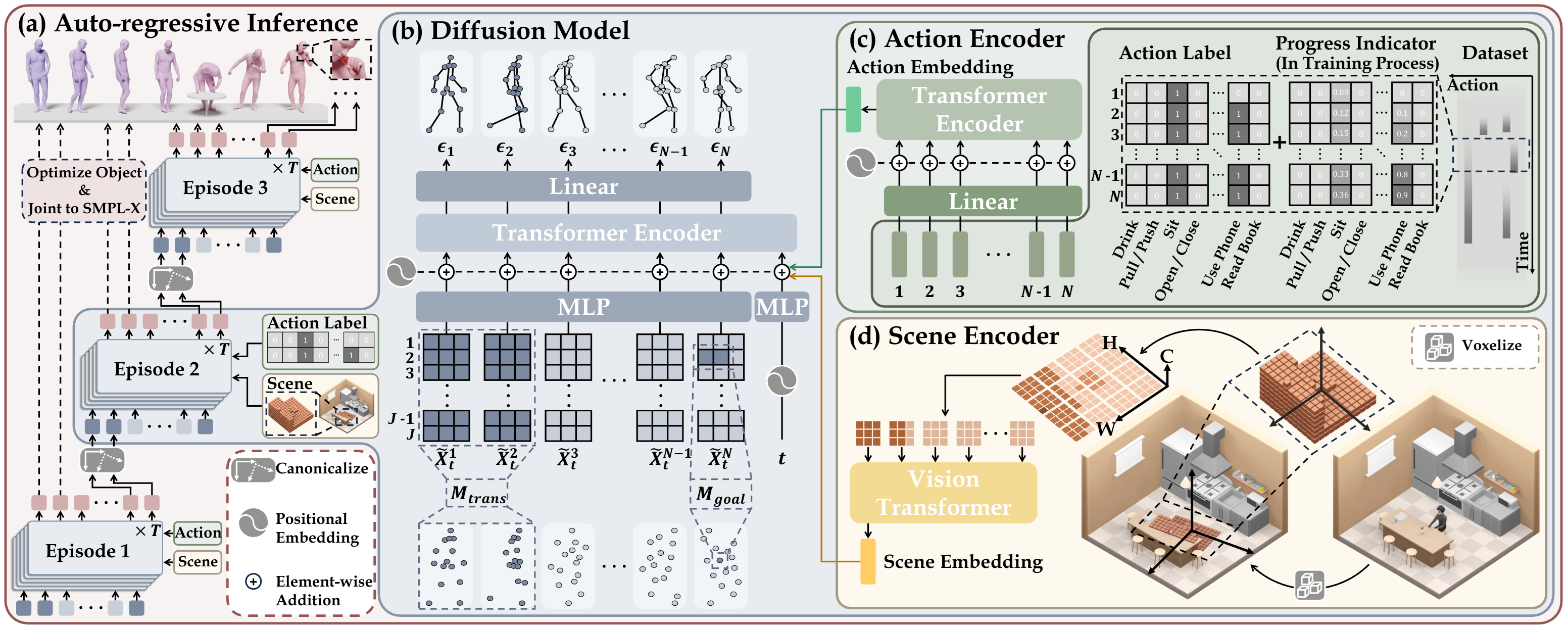
Scaling Up Dynamic Human-Scene Interaction Modeling
The advancing of human-scene interaction modeling confronts substantial challenges in the scarcity of high-quality data and advanced motion synthesis methods. Previous endeavors have been inadequate in offering sophisticated datasets that effectively tackle the dual challenges of scalability and data quality. In this work, we overcome these challenges by introducing TRUMANS (TRacking hUMan ActioNs in Scenes), a large-scale MoCap dataset created by efficiently and precisely replicating the synthetic scenes in the physical environment. TRUMANS, featuring the most extensive motion-captured human-scene interaction datasets thus far, comprises over 15 hours of diverse human behaviors, including concurrent interactions with dynamic and articulated objects, across 100 indoor scene configurations. It provides accurate pose sequences of both humans and objects, ensuring a high level of contact plausibility during the interaction. To further enhance adaptivity, we propose a data augmentation approach that automatically adapts collision-free and interaction-precise human motions. Leveraging the benefits of TRUMANS, we propose a novel approach that employs a diffusion-based autoregressive mechanism for the real-time generation of human-scene interaction sequences with arbitrary length. The efficacy of TRUMANS and our motion synthesis method is validated through extensive experimental results, surpassing all existing baselines in terms of quality and diversity. Notably, our method demonstrates superb zero-shot generalizability on existing 3D scene datasets (e.g., PROX, Replica, ScanNet, ScanNet++), capable of generating even more realistic motions than the ground-truth annotations on PROX. Our human study further indicates that our generated motions are almost indistinguishable from the original motion-captured sequences, highlighting their superior quality. Our dataset and model will be released for research purposes.
@article{jiang2024scaling,title={Scaling Up Dynamic Human-Scene Interaction Modeling},author={Jiang, Nan and Zhang, Zhiyuan and Li, Hongjie and Ma, Xiaoxuan and Wang, Zan and Chen, Yixin and Liu, Tengyu and Zhu, Yixin and Huang, Siyuan},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},journal={CVPR},year={2024},honor={Highlight}}
CVPR
Move as You Say Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
Despite significant advancements in text-to-motion synthesis, generating language-guided human motion within 3D environments poses substantial challenges. These challenges stem primarily from (i) the absence of powerful generative models capable of jointly modeling natural language, 3D scenes, and human motion, and (ii) the generative models’ intensive data requirements contrasted with the scarcity of comprehensive, high-quality, language-scene-motion datasets. To tackle these issues, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. By leveraging scene affordance maps, our method overcomes the difficulty in generating human motion under multimodal condition signals, especially when training with limited data lacking extensive language-scene-motion pairs. Our extensive experiments demonstrate that our approach consistently outperforms all baselines on established benchmarks, including HumanML3D and HUMANISE. Additionally, we validate our model’s exceptional generalization capabilities on a specially curated evaluation set featuring previously unseen descriptions and scenes.
@article{wang2024move,title={Move as You Say Interact as You Can: Language-guided Human Motion Generation with Scene Affordance},author={Wang, Zan and Chen, Yixin and Jia, Baoxiong and Li, Puhao and Zhang, Jinlu and Zhang, Jingze and Liu, Tengyu and Zhu, Yixin and Liang, Wei and Huang, Siyuan},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},journal={CVPR},year={2024},honor={Highlight}}
2023
Engineering
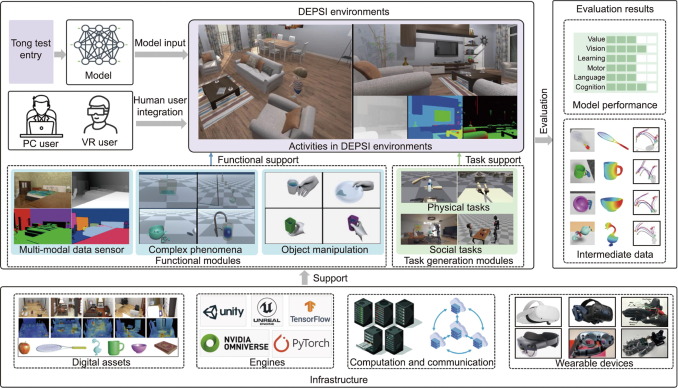
The tong test: Evaluating artificial general intelligence through dynamic embodied physical and social interactions
The release of the generative pre-trained transformer (GPT) series has brought artificial general intelligence (AGI) to the forefront of the artificial intelligence (AI) field once again. However, the questions of how to define and evaluate AGI remain unclear. This perspective article proposes that the evaluation of AGI should be rooted in dynamic embodied physical and social interactions (DEPSI). More specifically, we propose five critical characteristics to be considered as AGI benchmarks and suggest the Tong test as an AGI evaluation system. The Tong test describes a value- and ability-oriented testing system that delineates five levels of AGI milestones through a virtual environment with DEPSI, allowing for infinite task generation. We contrast the Tong test with classical AI testing systems in terms of various aspects and propose a systematic evaluation system to promote standardized, quantitative, and objective benchmarks and evaluation of AGI.
@article{peng2023tong,title={The tong test: Evaluating artificial general intelligence through dynamic embodied physical and social interactions},author={Peng, Yujia and Han, Jiaheng and Zhang, Zhenliang and Fan, Lifeng and Liu, Tengyu and Qi, Siyuan and Feng, Xue and Ma, Yuxi and Wang, Yizhou and Zhu, Song-Chun},journal={Engineering},year={2023},publisher={Elsevier}}
CVPR
Diffusion-based Generation, Optimization, and Planning in 3D Scenes
We introduce SceneDiffuser, a conditional generative model for 3D scene understanding. SceneDiffuser provides a unified model for solving scene-conditioned generation, optimization, and planning. In contrast to prior works, SceneDiffuser is intrinsically scene-aware, physics-based, and goal-oriented. With an iterative sampling strategy, SceneDiffuser jointly formulates the scene-aware generation, physics-based optimization, and goal-oriented planning via a diffusion-based denoising process in a fully differentiable fashion. Such a design alleviates the discrepancies among different modules and the posterior collapse of previous scene-conditioned generative models. We evaluate SceneDiffuser with various 3D scene understanding tasks, including human pose and motion generation, dexterous grasp generation, path planning for 3D navigation, and motion planning for robot arms. The results show significant improvements compared with previous models, demonstrating the tremendous potential of SceneDiffuser for the broad community of 3D scene understanding.
@article{Huang2023Diffusion,author={Huang, Siyuan and Wang, Zan and Li, Puhao and Jia, Baoxiong and Liu, Tengyu and Zhu, Yixin and Liang, Wei and Zhu, Song-Chun},title={Diffusion-based Generation, Optimization, and Planning in 3D Scenes},year={2023},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},journal={CVPR},}
CVPR
UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy
In this work, we tackle the problem of learning universal robotic dexterous grasping from a point cloud observation under a table-top setting. The goal is to grasp and lift up objects in high-quality and diverse ways and generalize across hundreds of categories and even the unseen. Inspired by successful pipelines used in parallel gripper grasping, we split the task into two stages: 1) grasp proposal (pose) generation and 2) goal-conditioned grasp execution. For the first stage, we propose a novel probabilistic model of grasp pose conditioned on the point cloud observation that factorizes rotation from translation and articulation. Trained on our synthesized large-scale dexterous grasp dataset, this model enables us to sample diverse and high-quality dexterous grasp poses for the object in the point cloud. For the second stage, we propose to replace the motion planning used in parallel gripper grasping with a goal-conditioned grasp policy, due to the complexity involved in dexterous grasping execution. Note that it is very challenging to learn this highly generalizable grasp policy that only takes realistic inputs without oracle states. We thus propose several important innovations, including state canonicalization, object curriculum, and teacher-student distillation. Integrating the two stages, our final pipeline becomes the first to achieve universal generalization for dexterous grasping, demonstrating an average success rate of more than 60% on thousands of object instances, which significantly out performs all baselines, meanwhile showing only a minimal generalization gap.
@article{Xu2023UniDexGrasp,author={Xu, Yinzhen and Wan, Weikang and Zhang, Jialiang and Liu, Haoran and Shan, Zikang and Shen, Hao and Wang, Ruicheng and Geng, Haoran and Weng, Yijia and Chen, Jiayi and Liu, Tengyu and Yi, Li and Wang, He},title={UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy},year={2023},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},journal={CVPR},}
ICCV
CHAIRS: Towards Full-Body Articulated Human-Object Interaction
Fine-grained capturing of 3D HOI boosts human activity understanding and facilitates downstream visual tasks, including action recognition, holistic scene reconstruction, and human motion synthesis. Despite its significance, existing works mostly assume that humans interact with rigid objects using only a few body parts, limiting their scope. In this paper, we address the challenging problem of f-AHOI, wherein the whole human bodies interact with articulated objects, whose parts are connected by movable joints. We present CHAIRS, a large-scale motion-captured f-AHOI dataset, consisting of 16.2 hours of versatile interactions between 46 participants and 74 articulated and rigid sittable objects. CHAIRS provides 3D meshes of both humans and articulated objects during the entire interactive process, as well as realistic and physically plausible full-body interactions. We show the value of CHAIRS with object pose estimation. By learning the geometrical relationships in HOI, we devise the very first model that leverage human pose estimation to tackle the estimation of articulated object poses and shapes during whole-body interactions. Given an image and an estimated human pose, our model first reconstructs the pose and shape of the object, then optimizes the reconstruction according to a learned interaction prior. Under both evaluation settings (e.g., with or without the knowledge of objects’ geometries/structures), our model significantly outperforms baselines. We hope CHAIRS will promote the community towards finer-grained interaction understanding. We will make the data/code publicly available.
@article{Jiang2022CHAIRS,author={Jiang, Nan and Liu, Tengyu and Cao, Zhexuan and Cui, Jieming and Chen, Yixin and Wang, He and Zhu, Yixin and Huang, Siyuan},journal={ICCV},title={CHAIRS: Towards Full-Body Articulated Human-Object Interaction},year={2023},booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},}
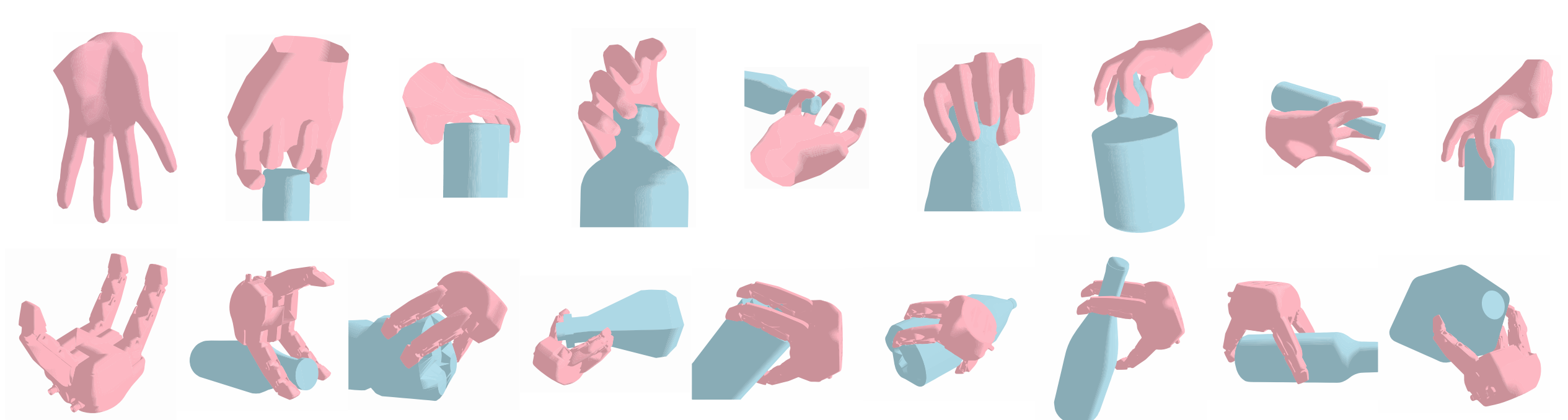
Generating dexterous grasping has been a long-standing and challenging robotic task. Despite recent progress, existing methods primarily suffer from two issues. First, most prior arts focus on a specific type of robot hand, lacking generalizable capability of handling unseen ones. Second, prior arts oftentimes fail to rapidly generate diverse grasps with a high success rate. To jointly tackle these challenges with a unified solution, we propose GenDexGrasp, a novel hand-agnostic grasping algorithm for generalizable grasping. GenDexGrasp is trained on our proposed large-scale multi-hand grasping dataset MultiDex synthesized with force closure optimization. By leveraging the contact map as a hand-agnostic intermediate representation, GenDexGrasp efficiently generates diverse and plausible grasping poses with a high success rate and can transfer among diverse multi-fingered robotic hands. Compared with previous methods, GenDexGrasp achieves a three-way trade-off among success rate, inference speed, and diversity.
@article{Li2022GenDexGrasp,title={GenDexGrasp: Generalizable Dexterous Grasping},author={Li, Puhao and Liu, Tengyu and Li, Yuyang and Geng, Yiran and Zhu, Yixin and Yang, Yaodong and Huang, Siyuan},journal={ICRA},publisher={IEEE},year={2023},}
ICRA
DexGraspNet: A Large-Scale Robotic Dexterous Grasp Dataset for General Objects Based on Simulation
Object grasping using dexterous hands is a crucial yet challenging task for robotic dexterous manipulation. Compared with the field of object grasping with parallel grippers, dexterous grasping is very under-explored, partially owing to the lack of a large-scale dataset. In this work, we present a large-scale simulated dataset, DexGraspNet, for robotic dexterous grasping, along with a highly efficient synthesis method for diverse dexterous grasping synthesis. Leveraging a highly accelerated differentiable force closure estimator, we, for the first time, are able to synthesize stable and diverse grasps efficiently and robustly. We choose ShadowHand, a dexterous gripper commonly seen in robotics, and generated 1.32 million grasps for 5355 objects, covering more than 133 object categories and containing more than 200 diverse grasps for each object instance, with all grasps having been validated by the physics simulator. Compared to the previous dataset generated by GraspIt!, our dataset has not only more objects and grasps, but also higher diversity and quality. Via performing cross-dataset experiments, we show that training several algorithms of dexterous grasp synthesis on our datasets significantly outperforms training on the previous one, demonstrating the large scale and diversity of DexGraspNet. We will release the data and tools upon acceptance.
@article{Wang2022DexGraspNet,title={DexGraspNet: A Large-Scale Robotic Dexterous Grasp Dataset for General Objects Based on Simulation},author={Wang, Ruicheng and Zhang, Jialiang and Chen, Jiayi and Xu, Yinzhen and Li, Puhao and Liu, Tengyu and Wang, He},journal={ICRA},publisher={IEEE},year={2023},honor={Outstanding Paper Candidate}}
2022
NeurIPS
HUMANISE: Language-conditioned Human Motion Generation in 3D Scenes
Learning to generate diverse scene-aware and goal-oriented human motions in 3D scenes remains challenging due to the mediocre characteristics of the existing datasets on Human-Scene Interaction (HSI); they only have limited scale/quality and lack semantics. To fill in the gap, we propose a large-scale and semantic-rich synthetic HSI dataset, denoted as HUMANISE, by aligning the captured human motion sequences with various 3D indoor scenes. We automatically annotate the aligned motions with language descriptions that depict the action and the individual interacting objects in the scene; e.g., sit on the armchair near the desk. HUMANISE thus enables a new generation task, language-conditioned human motion generation in 3D scenes. The proposed task is challenging as it requires joint modeling of the 3D scene, human motion, and natural language. To tackle this task, we present a novel scene-and-language conditioned generative model that can produce 3D human motions of the desirable action interacting with the specified objects. Our experiments demonstrate that our model generates diverse and semantically consistent human motions in 3D scenes.
@article{Wang2022Humanise,title={HUMANISE: Language-conditioned Human Motion Generation in 3D Scenes},author={Wang, Zan and Chen, Yixin and Liu, Tengyu and Zhu, Yixin and Liang, Wei and Huang, Siyuan},journal={NeurIPS},year={2022},}
2021
RA-L
Synthesizing Diverse and Physically Stable Grasps With Arbitrary Hand Structures Using Differentiable Force Closure Estimator
Existing grasp synthesis methods are either analytical or data-driven. The former one is oftentimes limited to specific application scope. The latter one depends heavily on demonstrations, thus suffers from generalization issues; e.g., models trained with human grasp data would be difficult to transfer to 3-finger grippers. To tackle these deficiencies, we formulate a fast and differentiable force closure estimation method, capable of producing diverse and physically stable grasps with arbitrary hand structures, without any training data. Although force closure has commonly served as a measure of grasp quality, it has not been widely adopted as an optimization objective for grasp synthesis primarily due to its high computational complexity; in comparison, the proposed differentiable method can test a force closure within milliseconds. In experiments, we validate the proposed method’s efficacy in 6 different settings.
@article{liu2021synthesizing,title={Synthesizing Diverse and Physically Stable Grasps With Arbitrary Hand Structures Using Differentiable Force Closure Estimator},author={Liu, Tengyu and Liu, Zeyu and Jiao, Ziyuan and Zhu, Yixin and Zhu, Song-Chun},journal={RA-L},volume={7},number={1},pages={470--477},year={2021},publisher={IEEE},}
T-PAMI
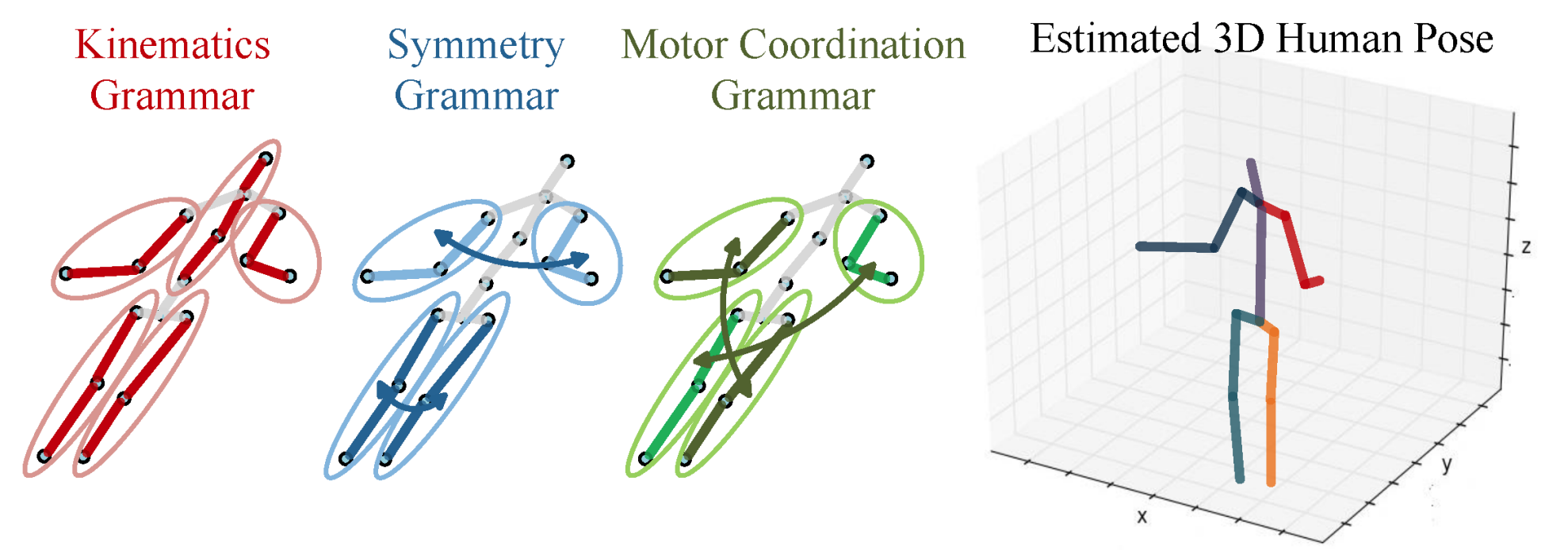
Monocular 3d pose estimation via pose grammar and data augmentation
In this paper, we propose a pose grammar to tackle the problem of 3D human pose estimation from a monocular RGB image. Our model takes estimated 2D pose as the input and learns a generalized 2D-3D mapping function to leverage into 3D pose. The proposed model consists of a base network which efficiently captures pose-aligned features and a hierarchy of Bi-directional RNNs (BRNNs) on the top to explicitly incorporate a set of knowledge regarding human body configuration (i.e., kinematics, symmetry, motor coordination). The proposed model thus enforces high-level constraints over human poses. In learning, we develop a data augmentation algorithm to further improve model robustness against appearance variations and cross-view generalization ability. We validate our method on public 3D human pose benchmarks and propose a new evaluation protocol working on cross-view setting to verify the generalization capability of different methods. We empirically observe that most state-of-the-art methods encounter difficulty under such setting while our method can well handle such challenges.
@article{xu2021monocular,title={Monocular 3d pose estimation via pose grammar and data augmentation},author={Xu, Yuanlu and Wang, Wenguan and Liu, Tengyu and Liu, Xiaobai and Xie, Jianwen and Zhu, Song-Chun},journal={T-PAMI},year={2021},publisher={IEEE},}